
Reliability: On the Path to 10G
By Alberto Campos
Historically in cable, network reliability did not require much attention. Early on, when our industry focus was video delivery, we promoted the amount and diversity of content, and ensured that technology kept up with the increasing video resolutions of TV sets. The Internet services boom came along and our focus steered towards delivering residential broadband services at higher and higher speeds. Our services have always driven how we design and deliver them and how we build and configure our networks.
Today, cable doesn’t focus just on video or residential high-speed data services, but as the comprehensive telecommunications platform cable has become, it now includes many services, serving not just residential customers but also enterprises. In addition to supporting entertainment video and high-speed data, cable also provides telephony, video conferencing, home security, gaming and many other services that bring along a very diverse set of requirements. The amount of information carried over our networks has drastically increased and so has its value. In this new environment, services have to be delivered with high reliability, meeting performance and availability thresholds associated with the various services.
We all have a general understanding of what reliability is. It is important however, to define it in the context of our networks and services. Reliability is the probability of a system or service lasting a defined period “t” without failures. Lasting without failures means to operate, perform or function within acceptable levels. In today’s world, cable networks encompass a plethora of services and applications. Each of these applications has its own criteria of what is acceptable. For example, the acceptability criteria for web-browsing services is very different than the criteria for gaming, video streaming or cellular backhaul. Since cable networks may carry all of these services concurrently, we need to simultaneously meet the performance demands for all these services.
The term reliability is extensively used, but many times, the metric that we actually refer to is availability. Reliability and availability are related but there is a subtle difference. Availability is defined as the fraction of time our system or service behaves as intended, meaning the percent of time it is available. Therefore, availability depends on two parameters, MTBF (mean time between failures) that tells us how frequently failures occur, and MTTR (mean time to restore or repair), indicating how soon service is restored. Reliability, on the other hand, only depends on MTBF.
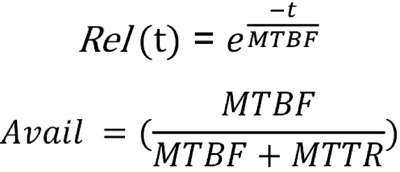
A lofty goal of the telecom industry is to achieve five 9s availability, in other words a system or service is available 99.999% of the time. This is equivalent to a system being unavailable less than 5 minutes and 15 seconds in a year. Even though it is quite a challenging undertaking to achieve across the entire network and suite of services, it is a good metric to be measured against to determine how close services or particular segments of the network is to performing at five 9s availability.
Operators should expect to collect extensive amounts of data to get a good handle on assessing reliability and availability. However, it is perhaps even more important that this data gathering commitment is accompanied by a company-wide commitment to follow all the processes and practices supporting a strategy towards reliability improvement. These processes include prevention, measurement, detection, analysis and resolution of failures.
Reliability in cable is not limited to the physical network infrastructure but it encompasses the management and provisioning systems and impacts procurement practices. This knowledge and experience on reliability performance of existing components will guide future purchase decisions.
These vast amounts of information are not just due to the extensive insight needed end-to-end across the network, but also because it extends across all network layers including physical, MAC, IP and application and service layers that are measured repeatedly in time. There is never too much data, as multiple sources and repeated measurements increase the confidence level of the information gathered.
Proactive network maintenance (PNM), which is now extensively used in the HFC portion of our networks, detects and solves problems before the customer is impacted. PNM inherently increases MTBF and therefore, improves reliability and availability. Since availability also depends on MTTR, or how fast service is restored, it is valuable to include an availability impact assessment as part of network planning and evolution decisions. Concepts of PNM and reliability go hand in hand, and it is advantageous to extend these concepts beyond the coaxial portion of our networks. Pursuing an automation strategy generates similar benefits as PNM. Evolving from manual reconfiguration and provisioning towards automated processes enables, as a by-product, fast restoration and higher availability.
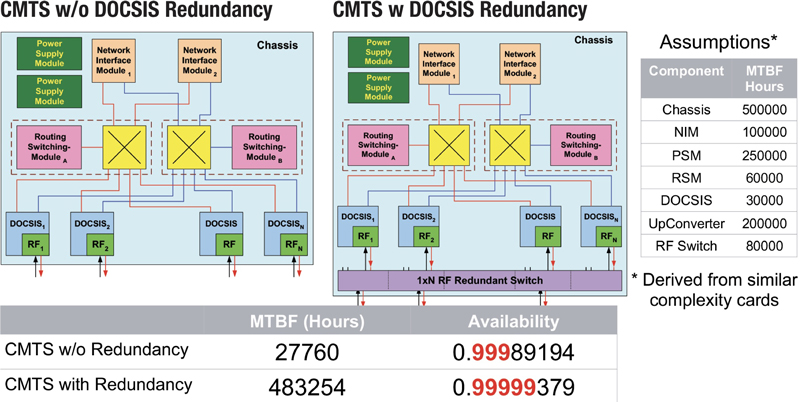
Just as important to assessing the durability and resiliency of individual components one uses, is to understand how these components are architected into systems. Leveraging CMTS availability analysis we illustrate the benefits of reliability-aware system design. Comparing a CMTS designed without RF redundancy to one that has RF redundancy, we obtain an availability difference from below four 9s to better than five 9s, even though most of the components used are the same.
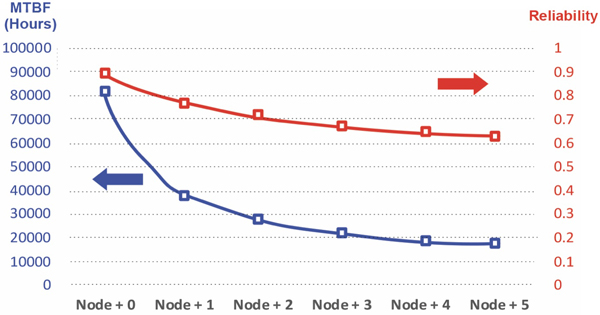
As the demand for capacity causes us to push fiber deeper, we have the opportunity to improve the reliability of our networks. This improvement is not only due to improving reliability as the node size decreases, but as fiber penetrates deeper, there is the opportunity to close the fiber loops to achieve redundancy. There are substantial revenue opportunities in enterprise connectivity services that value higher availability and redundancy. Incorporating reliability concepts as an integral part of the network architecture evolution could significantly improve network reliability.
An area that has not been given sufficient attention is that of software reliability. In today’s world, software is pervasive in all aspects of our lives and our networks are no exception. From our components’ operating systems, our networking protocols, our maintenance and management systems to our back office, every aspect of cable depends on software. We accept software bugs as part of the development process. Their impact depends on how well one troubleshoots, but it is never foolproof. Assessing software reliability is as important as assessing reliability of the more obvious infrastructure and devices. Designing with software reliability in mind helps diminish software failure impact. In this era where we virtualize more and more of our network functions, software reliability takes on an even more important role.
The economic benefits of operational-impacting activities are not always apparent, however, an appreciation for the benefits of not having to replace hardware so often, knowing which components will last longer, understanding which components are a better investment for your money, having a feedback loop with vendors so that they can improve their products and also having leverage with them on discounts when products don’t meet reliability targets are all noticeable benefits when we quantify them. New services represent new revenue opportunities with enterprise, wireless backhaul and data center connectivity with SLAs that you can meet and revenue you can target. Reliability is not just the responsibility of operational teams, but should be the way of thinking for the entire organization. It is relevant to engineering, strategy and sales to design and plan new services that require a certain level of performance and specific SLAs. The entire supply chain is involved as procurement teams make sure that the components you buy last longer.
As we embark in the direction toward a 10G world, the relevance of reliability as an integral part of our business, and operations, engineering and planning activities become more relevant. In this 10G era where capacity and proliferation of new services is growing exponentially, the time to act and prepare for that future is now.
 Dr. Alberto Campos,
Dr. Alberto Campos,
Fellow, CableLabs®
a.campos@cablelabs.com
Dr. Campos has over 30 years of experience in cable, DSL, wireless, and optical communications. He is a prolific author with over 40 patents granted, and holds BSEE, MSEE, and Ph.D. degrees from Northeastern University. Dr. Campos joined CableLabs in 2002, where he conducted seminal work in proactive network maintenance, DOCSIS® specifications, and coherent optics. He gained the distinction of being CableLabs’ first Fellow in 2017, and his proactive network maintenance and coherent optics work has served as catalyst to numerous transformative innovations for the cable industry. On several occasions, Dr. Campos has been named CableLabs’ Inventor of the Year and he is the current recipient of CableFax’s 2019 “Engineer of the Year” Award. He recently published the book “Coherent Optics for Access Networks” through the CRC press.

