
Into the Fire…
By Charles Allred and David Ririe
About a year and a half ago, some equipment intended to enable a new technology known as remote PHY began to arrive in the Cox Access Lab. Along with the equipment came the promise that it would revolutionize how a cable operator approaches the deployment of high speed data and video services. Any engineer who has worked with DOCSIS for any length of time would understand we were excited to get to work figuring out how remote PHY integrates into our network.
We already had extensive experience with a partially distributed architecture leveraging a modular CMTS with our DOCSIS 3.0 deployments. DOCSIS 3.1 came along and much to our relief, CMTS vendors embraced a return to an integrated CCAP. Gone were the edge-QAM modulators, DTI clocks, switches, VLANs, countless SFPs, and hundreds of meters of pink fiber optic cable piled like giant heaps of cotton candy on the data center floor as each M-CMTS chassis was decommissioned. We had returned to a simpler time, and took comfort that we only had to manage a single device again. With remote PHY it became clear our return to the simple life was short lived. Some might even say we were about to wish for the good old days of M-CMTS, which was at least all contained in the same facility! The transition to a fully distributed environment in remote PHY would again decouple the downstream PHY from the CCAP, and while we are at it, how about the upstream as well? Initially we thought, “We’ve done modular CMTS before, how hard can a modular CCAP possibly be?”
Things started off innocently enough. A simple Layer 2 switch was employed for RPD to CCAP core, communication reminiscent of our M-CMTS days. PTP clocks took the place of the old DTI clocks to keep CCAP cores and RPDs in sync. Our DHCP servers were gently coaxed to serve up the required options to the RPDs so they would know which core to talk to. A few lines of config on the core… and success. We had our first RPD online with some actual cable modems running traffic. But what if we wanted another RPD… or a thousand? Our L2 switch worked fine for a proof of concept, but was a bit limiting. We would be restricted to groups of RPDs permanently tied to CCAP cores requiring physical rewiring to move them to another core.
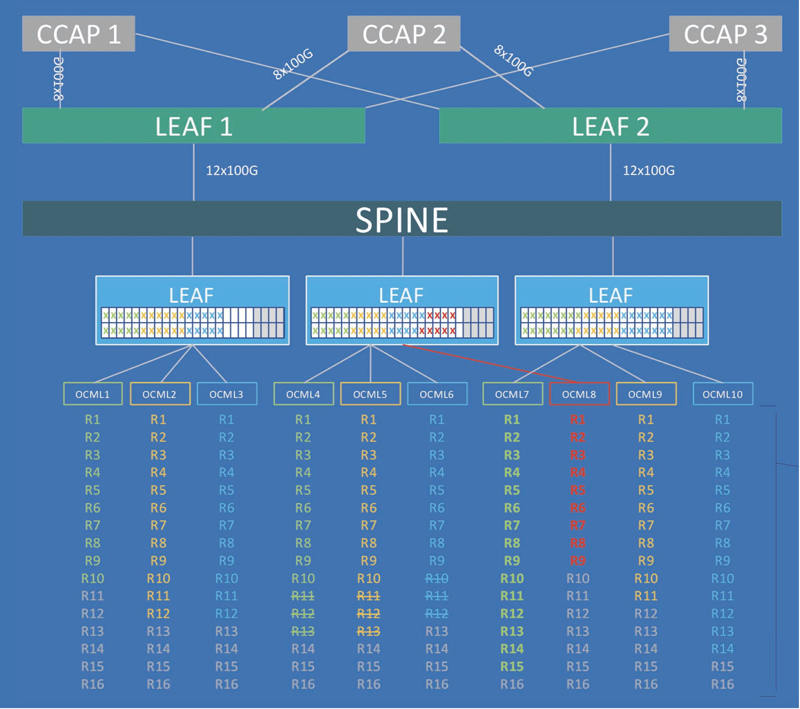
The Layer 2 converged interconnect network with its fixed VLANs and trunk ports gave way to a spine and leaf Layer 3 network which allowed us to host any RPD on any CCAP core. IPv4 was finally on its last leg (at least in this part of the access network!), and all traffic is transported exclusively using IPv6. While IPv6 isn’t anything new for Cox1, this was the first time we had deployed an IPv6-only network.
It also became clear the project was going to affect a lot more than the usual DOCSIS team members. A cross functional team was assembled consisting of representatives from nearly the entire technology organization to discuss the various deployment challenges and begin solving them2.
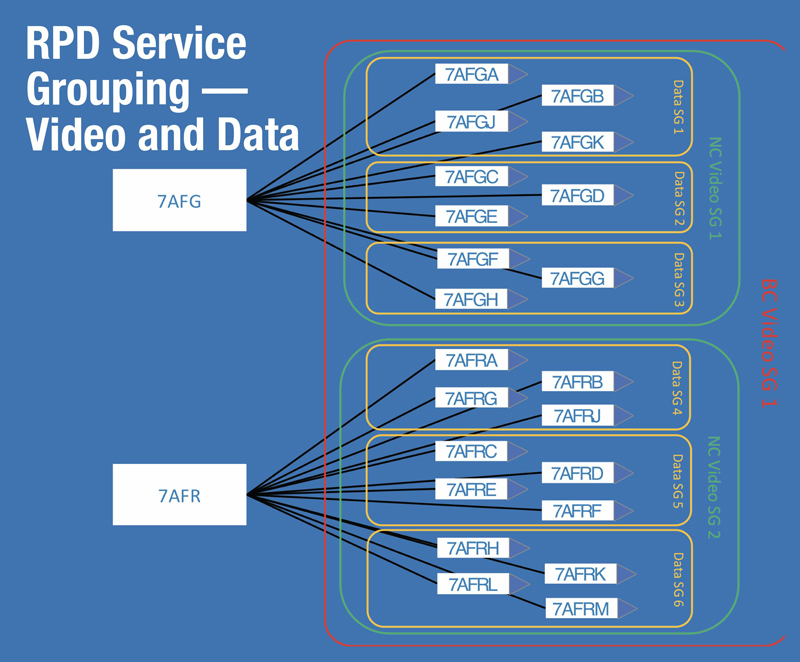
Discussions were centered around the challenges of provisioning RPDs and managing their near infinite planned flexibility. Not content to just map an RPD to a CCAP core, we wanted the flexibility to map an RPD to any number of CCAP cores: each one serving up DOCSIS, VOD, SDV, and/or broadcast video. Many other discussions arose around concerns with end-to-end visibility and troubleshooting of the solution. In sharp contrast to our impressions from the initial lab testing, it turns out scaling thousands of RPDs could prove to be a bit more challenging.
To solve the scaling issue, we needed a mechanism to keep track of every RPD, every CCAP core, that core’s interfaces, and every DOCSIS, narrowcast and broadcast service group. For each DOCSIS service group type there may be one or more RPDs associated. Narrowcast, approximately 16. Broadcast service groups would be joined by every RPD on the CCAP and in the future potentially every RPD in a facility. Our chosen DHCP servers couldn’t manage the needed level of complexity even if backed up by another database pushing the associations into its APIs. We needed a more robust, accessible, and flexible automation tool.
We began trialing an orchestration system intended to automate some of the more tedious aspects of the provisioning process. The primary function is to act as a repository of all RPD-to-service group mappings, directing RPDs to the desired CCAP cores, and to configure those cores to accept the RPDs. In theory this seemed like it could solve many of our provisioning problems. Like all things remote PHY related, the system is still in its infancy. As it turns out, human beings are quite good at intuitively deciding what a valid CCAP core configuration looks like. Even when they get it wrong it is still likely it will work well enough. Machines only do what they’re told and will dutifully configure things in strange and unexpected ways – all while proclaiming complete success. Many hours were spent troubleshooting these issues and communicating requirements to support the corner cases often at the root of these human/machine misunderstandings.
While we were successful with our initial orchestration system, there are still areas left to expand upon. Scalability is a bit of an unknown, but we will work through that as our remote PHY deployments grow. There is also substantial integration work to be done to blend the system into our existing tools. Once complete, its functions should be invisible to most of our support teams.
Visibility of an RPD’s health and its configuration is equally critical to the operation of our network. There are an overwhelming number of data points to consider. The RPD’s name, geolocation, temperature, connected cores, PTP clock state, Ethernet link utilization, and joined multicast groups are only a few. Who’s to say which data is relevant in any given situation? Does it matter if the RPD is operating at 180 °F while the lid switch is in alarm and someone is watching VOD re-runs of Lost? Probably. Like our configuration automation efforts, our monitoring systems will need to be trained to wade through the sea of metrics to identify key events and notify the correct person in the event of an outage and ensure the fastest resolution. Ideally, we should teach the monitoring system to identify sets of leading indicators and notify a human before they manifest as an actual customer outage.
None of this even addresses the challenges we faced with video integration. That topic is certainly worthy of an article all by itself. At the end of the day, remote PHY certainly does live up to its revolutionary promise. How hard can this be, indeed…

Charles Allred
Cable Access Engineer
Cox Communications, Inc.
charles.allred@cox.com
Charles Allred is a Cable Access Engineer at Cox Communications. He spent nine years at Cox in the Phoenix market where he was involved in their first DOCSIS 3.0 deployments. In 2016 he joined the Atlanta Access Engineering team where his current focus is around modular CCAP and remote PHY deployments.
 David Ririe
David Ririe
Sr. Director, Access Engineering
Cox Communications, Inc.
david.ririe@cox.com
David Ririe serves as a Senior Director in the Access Engineering group for Cox Communications in Atlanta, GA. He has worked in various engineering roles for Cox Communications starting as a Network Engineer in the Omaha, NE market 14 years ago. He has lead the team through a number of transitions and upgrades on both the DOCSIS and PON technology platforms in that time. He began his telecom career in the U.S. Air Force working on various communications and data networking platforms in the air and on the ground.
Image: Shutterstock

